I came across an article on r/programming about handling creating 100k short URLs per second 1.
What a convoluted overengineered mess!
Don’t get me wrong, I love over-engineering, but only for hobbyist learning projects. As many reddit comments rightly pointed out, schools rarely teach anything about distributed systems or software architecture. When new people join the industry, blog posts from these seemingly authoritative tech-leads will make them think overengineering is the way to do things. Often, the solution can be much simpler.
Enough ranting. Let’s get technical!
The requirements
- There’s really not much to it. You give it a long URL, you get back a short URL. There are a few fluff pieces like allowing the caller to pick the short string, but those are inconsequential to the overall architecture.
- It works and it can support 100K writes/second. Since OP didn’t mention, let’s assume 1M reads/second.
- No duplicate long URL (NFR-1 in the original post). This requirement is a bit questionable and we’ll discuss it a bit later.
This is the example request and response that OP provided:
// Request:
{
"long_url": "https://example.com/very/long/url",
"custom_domain": "short.myapp.com", // Optional
"custom_alias": "mycustomalias" // Optional
}
// Response:
{
"short_url": "https://short.myapp.com/mycustomalias",
"long_url": "https://example.com/very/long/url",
"alias": "mycustomalias",
"domain": "short.myapp.com"
}
The solution
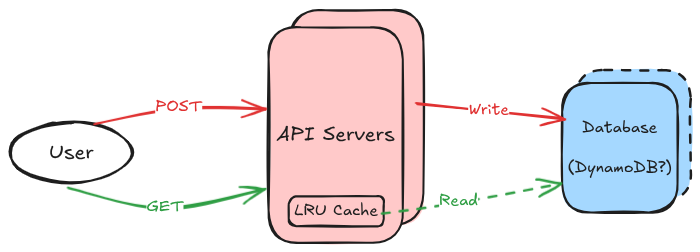
The overall flow is simple:
- We have the user, the API servers—each having an in-memory cache, and the database servers.
- When a user makes a POST request, the request will hit one of the many API servers, which then will write through to the database.
- When a user makes a GET request, the API server handling the request will first check the LRU cache, and only read from the database when there’s a cache miss. Most GET requests should be served directly without ever reaching the database. Even if there are a lot of cache misses for some reason, DynamoDB would still be able to handle the read traffic (see below).
Let’s dive into each component:
- The database:
- Some napkin math: short URL + long URL, generously about 300-500 bytes all together. At 100K writes/s, let’s say we are writing 50,000 KB/s.
- I went with DynamoDB to be consistent with OP, but any modern reliable key-value store will do. DynamoDB can handle 40,000KB write/s, or 80,000KB write/s when pre-provisioned. I believe one single table would largely work, and it seemed to work for OP.
- Just to be generous and abanduntly cautious, we’ll shard our data into two DynamoDB instances: sharding by hashing the short URL. For example:
hash("shorturl.com/a") => db1andhash("shorturl.com/b") => db2. This will more than double the write capacity we need.
Edit: some pointed out that the DynamoDB limits above were just the default limits and one could request Amazon for an increase. In that case, there’s no need to manually shard DynamoDB. For the other databases without sharding built-in, this still applies.
-
The LRU cache:
- If you’re not familiar with LRU cache, it is a map or dictionary that you can put a capacity on the maximum number of items it contains. When you put in more items and goes over the capacity, the item which was Least Recently Used gets removed. In this case, we can use it to do something like keep the last 1 million requested URLs in memory. LRU libraries are abundant just from my quick searches for Go, C#, Python, Node, Ruby, etc.
- Keeping the same assumption of 500 bytes like above, padding for things such as languages store strings in UTF-16, additional data structures to make LRU work, let’s call it 1KB per entry. Keeping 1 million entries in memory will only cost us a whooping 1GB of RAM. Most production grade API servers can comfortably hold 5x or 10x the number of entries.
- Since URL shortening are immutable, the cache hit rate will be exceptionally high. Only a small percentage of the GET requests will actually hit the database—which DynamoDB can easily tank.
-
The actual API servers
- At 1 million requests/second, with most requests serving directly out of memory, about a handful to a dozen API servers will do the job.
- With this setup, we can also easily scale up and down the number of API servers without severely impacting the rest of the architecture (i.e. the database).
That’s it. That’s all there is to a URL shortener service that can serve the level of traffic OP needed. No convoluded queues and EC2 workers.
Now let’s talk about that "requirement 3"
In the article, OP stated a non-functional requirement (NFR-1) that each long URL can only have one corresponding short URL. For example, this requirement means it’s illegal to have "short.com/a" and "short.com/b" both point to "long.com/x". OP already flip flopped on in the reddit comments 2, even though the solution also clearly tried to solve for it.
- First of all, this is a weird requirement. No URL shortener I knew or ran ever needed that as a requirement. If that’s purely a requirement to save a few bytes in storage, congratulations on the dumbest trade off ever made.
- Secondly, even if somehow we need to satisfy such a requirement, there’s still no need for the mess OP created. All you would have to do is store the reverse
longurl => shorturlkey value. This will allow two things:- Having a definitive shard for a given long URL where you can check for duplicates. This will allow the database to scale horizontally rather than having to scan through the secondary indices of each shard.
- Allow the kind of reporting OP needed such as listing out all the short links for the given domain by fanning out to just the small number of shards we have.